LEC 03
에이전트는 사전에 map을 모르는 채로 움직이며, 매 행동이 끝난 뒤에 상태 정보를 받는다.
따라서, 길을 알려주는 행동대장을 따라갈 필요가 있는데, 이때 등장하는 Q형님이 바로 행동대장이다.

Frozen Lake 게임을 Q형님과 함께 수행해본다.
Q형님에게 입력할 값은 2개 : (1) state 현재 위치 / (2) action 다음에 취할 행동(상하좌우 중 이동할 방향)
그러면, Q형님은 각 행동 별 확률(가능성)을 알려준다.
이제, Q형님의 가르침대로 4방향 중 최대값을 가지는 방향을 찾아 이동하면 된다.

Max Q = maxQ(s1, a') : 최대 확률값
argmax Q(s1, a) : 그 최대 확률에 해당하는 행동 (ex. 오른쪽)
=> Optimal policy *
그렇다면, 이 행동대장 Q는 어떻게 학습시킬까?

나는 현재 s에 있고 a의 행동으로 s'로 움직일 것이다. -> 즉, Q(s, a))
이때, s'로 움직였을 때 받을 reward(r)를 알고 있으며, Q(s', a')도 알고있는다고 믿는다.
그러면, Q(s,a) = r + max Q(s', a') 로 표현할 수 있다.

Q(s,a) = r + max Q(s', a') 를 반복 사용해서 16*4 table을 학습시켜본다.

먼저 테이블을 '움직일 공간 수(env.observation_space.n) * 행동 수(env.action_space.n)'크기의 0 으로 초기화한다.
다음,
{ 현재 위치(s)에서 다음 행동(a)을 랜덤으로 선택한다.
행동 a를 취하여 s'으로 이동하였을 때 얻을 reward와 미리 알고 있는 max Q(s',a')값을 더해 Q(s,a) 값을 구한다.
그리고 현재 위치를 s'로 갱신한다. }
다음 작업을 게임이 끝날 때까지 반복한다. (goal에 도착하거나 or hole에 빠지거나)
LAB 03
Windows10 Code
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
import gym
import numpy as np
import matplotlib.pyplot as plt
from gym.envs.registration import register
import random as pr
def rargmax(vector): # 최댓값 선택 (모든 액션 기댓값이 0이라면, 랜덤하게 액션선택)
m = np.amax(vector)
indices = np.nonzero(vector == m)[0]
return pr.choice(indices)
env_dict = gym.envs.registry.env_specs.copy()
for env in env_dict:
if 'FrozenLake-v3' in env:
del gym.envs.registry.env_specs[env]
register(
id='FrozenLake-v3',
entry_point='gym.envs.toy_text:FrozenLakeEnv',
kwargs={'map_name': '4x4','is_slippery':False}
)
env = gym.make('FrozenLake-v3')
Q = np.zeros([env.observation_space.n, env.action_space.n]) # Q table 0으로 초기화
num_episodes=2000
rList=[]
for i in range(num_episodes):
state = env.reset()
rAll = 0
done = False
while not done:
action = rargmax(Q[state, :])
new_state, reward, done, _ = env.step(action)
Q[state,action] = reward + np.max(Q[new_state, :])
rAll += reward
state = new_state
rList.append(rAll)
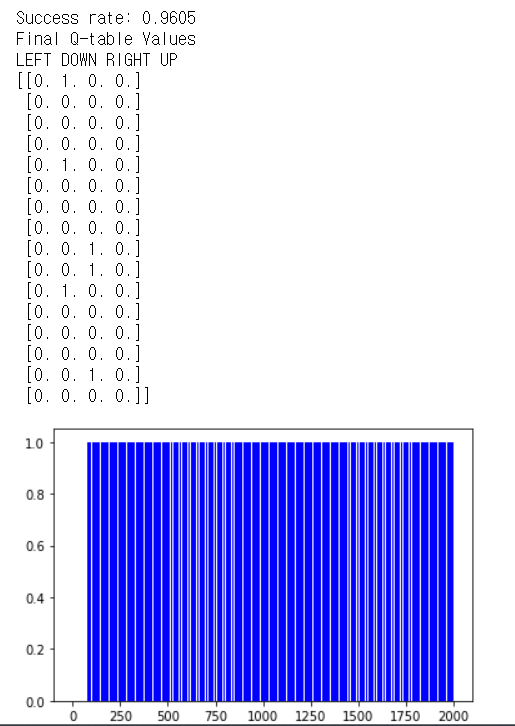
print("Success rate: " + str(sum(rList)/num_episodes))
print("Final Q-table Values")
print("LEFT DOWN RIGHT UP")
print(Q)
plt.bar(range(len(rList)), rList, color='blue')
plt.show()
|
cs |
Reference:
[1]: http://hunkim.github.io/ml/
[2]: https://youtu.be/Vd-gmo-qO5E
[3]: https://youtu.be/yOBKtGU6CG0Lab2
'ML&DL > Sung Kim's RL Lecture' 카테고리의 다른 글
| LEC 06. Q-Network (0) | 2021.01.08 |
|---|---|
| LEC 05. Q-learning on Nondeterministic Worlds! (0) | 2021.01.08 |
| LEC 04. Q-learning (table) (0) | 2021.01.07 |
| LEC 02. Playing OpenAI GYM Games (0) | 2021.01.06 |
| Lec 01. RL Introduction (0) | 2021.01.06 |