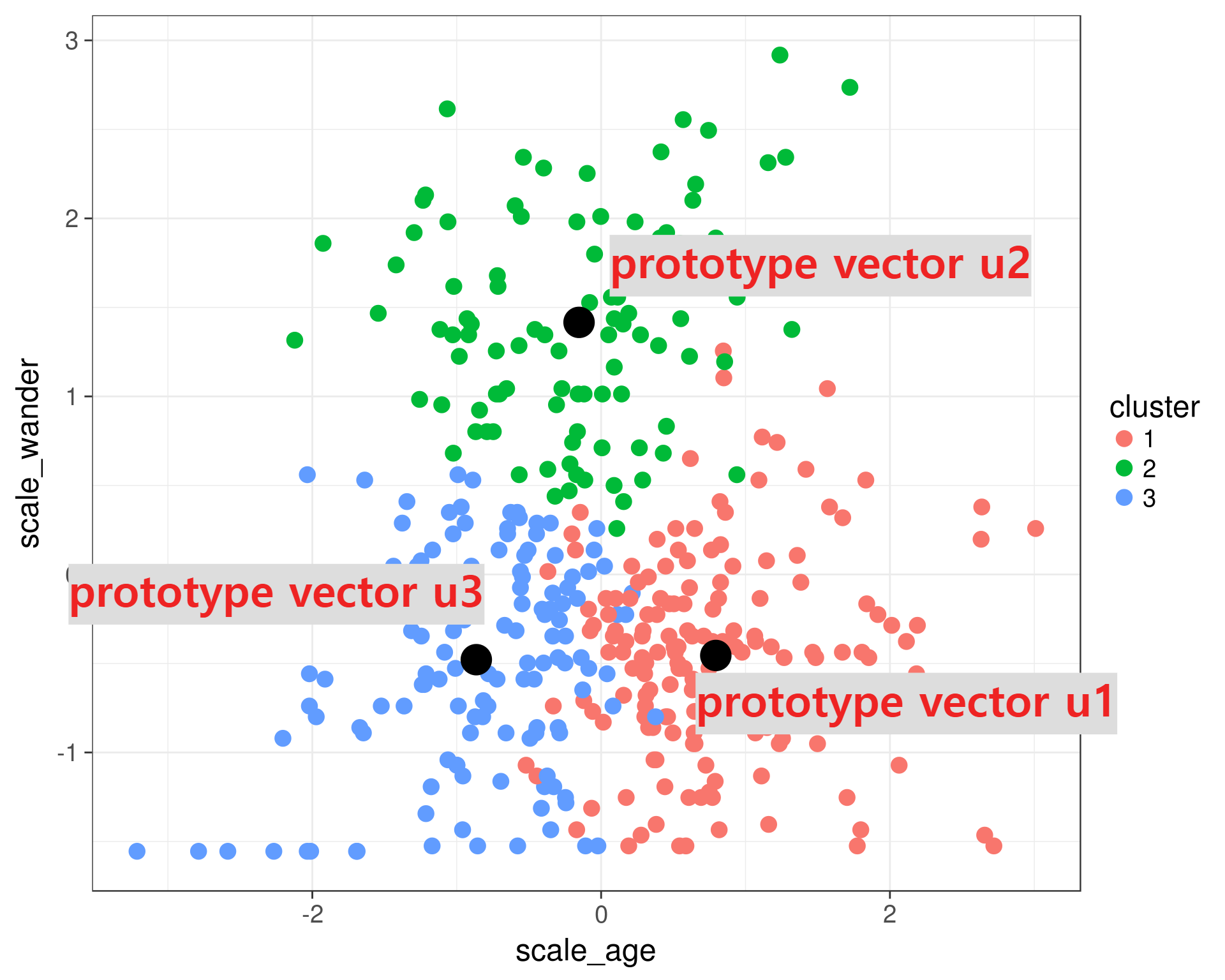
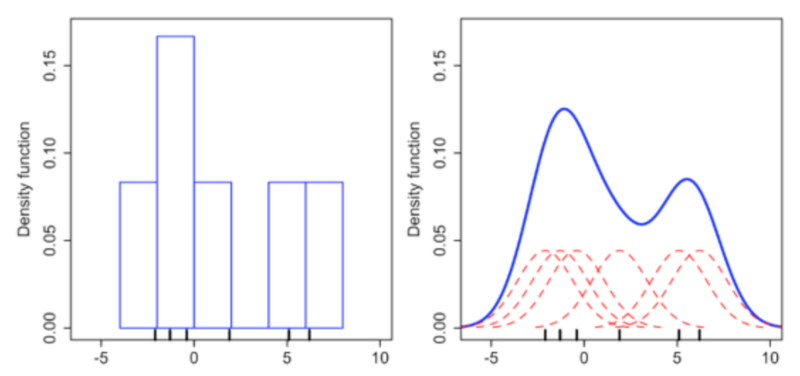
목차 강화학습의 적용분야는 상당히 넓다. Optimal decision making하는 분야라면 다 적용가능하다! RL과 다른 머신러닝의 차이점은 agent가 action(환경과의 상호작용)을 통해 얻는 reward signal(delay 될 수 있음)이다. Reward agent 가 받는 피드백으로, 현재 timestep t에서 얼마나 잘했는가를 알 수 있다. agent는 cumulative reward를 최대화해야한다. RL reward hypothesis : 모든 goal은 expected cumulative reward의 최대화로 표현 가능하다. (동의하는가?!) History 현재 timestep t까지의 일련의 observation, action, reward를 의미한다. H_t = O_1, ..