목차
LSTM으로 주식 예측하기
이번 포스팅에서는 특정 종목의 가격(상승 or 하락)을 예측하는 LSTM 모델을 생성합니다.
모델의 input으로 Transfer entropy를 도입하여 특정 종목에 대한 KOSPI의 영향력을 반영합니다.
1. 주식 데이터 Load
1.1 모듈 import
%pip install yfinance
%pip install pandas-datareader
from pandas_datareader import data as pdr
import yfinance as yf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import math
import random
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.data import TensorDataset
from torch.utils.data import Dataset
from sklearn.metrics import mean_squared_error
import argparse
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import KBinsDiscretizer
yf.pdr_override()
1.2 yfinance 주식 데이터 불러오기
pdr.get_data_yahoo(company_ticker, start = start_time, end =end_time) 를 통해 yfinance에서 주식 데이터를 불러옵니다.
특정 주식의 ticker 정보와 원하는 기간(start_time ~ end_time)을 설정해야합니다. ticker정보는 https://finance.yahoo.com/ 여기서 원하는 종목을 검색하시면 됩니다. 예를 들어, 삼성 전자의 경우, ticker는 '005930.KS' 입니다.

필자는 comopany_ticker로 삼성 전자, market_ticekr를 kospi로 설정 후, 2022-01-01 ~ 2020-06-01기간의 주식데이터를 받아왔습니다.
그 결과, column이 {Open, Hihg, Low, Close, Adj Close, Volume}인 'DataFrame' 형식의 주식 데이터를 얻을 수 있습니다.
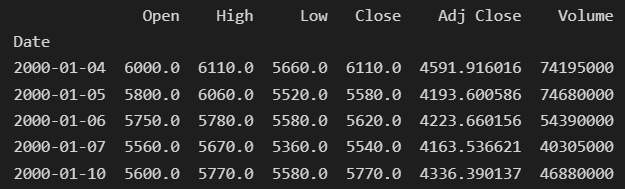
def load_data(company_ticker,market_ticker, start_time, end_time,num_bin,bin_strategy,prob):
company = pdr.get_data_yahoo(company_ticker, start = start_time, end =end_time)
market = pdr.get_data_yahoo(market_ticker, start = start_time, end =end_time)
#Get only intersection of 2 dataframes, company and market by excluding complement set of index
company, market = get_intersection_data(company,market)
assert len(company)==len(market)
#Calculate 'Log Return' value and add to new column : 'Log Return'
company, market = add_LogReturn(company, market)
company['Log Return'] = company['Log Return'].fillna(0)
market['Log Return'] = market['Log Return'].fillna(0)
#Calculate 'Log-Return_bin' value and add to new column : 'LR_bin'
company, market = add_LogReturnBin(company, market,bin_strategy, num_bin, prob)
return company, market
1.3 데이터 feature 생성 : log return & log return bin
! log return과 log return bin대신 실제 값을 feature로 사용하여 싶은 분은 해당 과정을 생략해주셔도 됩니다.
주로 Close 혹은 Adj Close column의 값에 scaler를 적용하여 정규화한 값을 feature로 사용하는 거 같습니다.
다음으로, log_return(로그 수익률)과 log_return_bin값을 계산하고 해당 값을 기존의 데이터프레임에 새로운 column으로 추가해주었습니다.
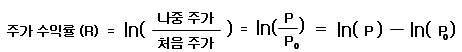
log return(로그 수익률)을 사용한 이유는 아래 포스팅에서 잘 설명해주고 있습니다.
[페어 트레이딩/기초편] 6. 로그 수익률 – 인사이트캠퍼스
insightcampus.co.kr
추가로, log return bin을 구해준 이유는 model의 feature로 transfer entropy를 사용했기 때문입니다. transfer entropy를 계산하는 과정에서 discrete probability가 필요하여 log return값을 sklearn.preprocessing import KBinsDiscretizer를 사용하여 binning하였습니다. binning시에는 train 데이터를 기준으로 'kmeans' stratege를 적용한 KBinsDiscretizer를 생성하였습니다. 필자는 10개의 bin을 만들었고, 각 bin에 해당하는 데이터의 수를 다음과 같이 확인할 수 있습니다.company데이터의 경우, -0.1615 ~ -0.1107사이의 log return값은 bin 0, -0.1107 ~ -0.0650은 bin 1으로 대체됩니다.


def get_intersection_data(company,market):
company = company[company.index.isin(market.index)]
market = market[market.index.isin(company.index)]
return company, marketdef add_LogReturn(company, market):
company['Log Return'] = np.log(company['Adj Close']/company['Adj Close'].shift(1))
market['Log Return'] = np.log(market['Adj Close']/market['Adj Close'].shift(1))
return company, marketdef plot_LogReturnBin(X,num_bin):
plt.hist(X, bins='auto')
plt.xticks(list(np.arange(num_bin)))
plt.show()
def add_LogReturnBin(company, market, bin_strategy, num_bin, prob):
train_size = int(len(company)*prob)
est = KBinsDiscretizer(n_bins=num_bin, encode='ordinal', strategy=bin_strategy)
company_tmp = np.array(company['Log Return']).reshape(-1,1)
#**Fit : only Train data & Transform : train+test
est.fit(company_tmp[:train_size])
company['LR_bin'] = est.transform(company_tmp)
# Convert single column to int dtype.
company['LR_bin'] = company['LR_bin'].astype('int')
print('** [Binning Result] \n (1) Company Bin edges: ',est.bin_edges_[0])
unique_q, counts_q = np.unique(company['LR_bin'].values, return_counts=True)
print(dict(zip(unique_q, counts_q)))
#plot_LogReturnBin(company['LR_bin'].values,est.n_bins_[0])
market_tmp = np.array(market['Log Return']).reshape(-1,1)
#**Fit : only Train data & Transform : train+test
est.fit(market_tmp[:train_size])
market['LR_bin'] = est.transform(market_tmp)
market['LR_bin'] = market['LR_bin'].astype('int')
print('(2) Market Bin edges: ',est.bin_edges_[0])
unique_q, counts_q = np.unique(market['LR_bin'].values, return_counts=True)
print(dict(zip(unique_q, counts_q)))
#plot_LogReturnBin(market['LR_bin'].values,est.n_bins_[0])
return company, marketcompany_ticker = '005930.KS' #Samsung Ticker
market_ticker = "^KS11"
start_time = "2000-01-01"
end_time = "2020-06-01"
company, market = load_data(company_ticker, market_ticker, start_time, end_time, num_bin,bin_strategy,prob=train_prob)2. 학습 데이터 생성
2.1 Transfer entropy
앞서 log return bin을 구해준 이유는 model의 feature로 transfer entropy를 사용했기 때문이라고 하였습니다. transfer entropy를 통해 두 시계열 데이터 X, Y가 있을 때, Y가 X에 영향을 얼마나 미치는 지 파악할 수 있습니다. 필자는 kospi를 Y로 두고, kospi가 특정 회사(삼성)에 얼마나 영향을 미치는 지 계산하였습니다.
Transfer entropy구현은 해당 포스팅을 참고하였습니다 :)
https://mons1220.tistory.com/154#comment16969198
[예제] 시계열 Data로부터 Transfer Entropy 구하기
정보 엔트로피를 소개하는 글에서 언급되었던 Transfer entropy. 수식과는 다르게 실제로 구하는 방법은 감이 쉽게 오지 않는다. 그래서 관련 예제를 정리해본다. 잠깐 복습을 하자면, Transfer entropy는
mons1220.tistory.com
def cal_TE_Y2X(companyLR, marketLR, num_bin):
""" Count """
M_0 = np.zeros((num_bin, num_bin, num_bin)) # p(x_n+1, x_n, y_n)
M_1 = np.zeros((num_bin,num_bin)) # p(x_n+1, x_n)
M_2 = np.zeros((num_bin,num_bin)) # p(x_n, y_n)
M_3 = np.zeros(num_bin) # p(x_n)
for t in range(len(companyLR)):
if t+1 != len(companyLR):
M_0[companyLR[t + 1], companyLR[t], marketLR[t]] += 1
M_1[companyLR[t + 1], companyLR[t]] += 1
M_2[companyLR[t], marketLR[t]] += 1
M_3[companyLR[t]] += 1
""" Count -> Probability"""
M_0 = M_0 / M_0.sum()
M_1 = M_1 / M_1.sum()
M_2 = M_2 / M_2.sum()
M_3 = M_3 / M_3.sum()
TE_Y2X = 0
for x_n1 in range(num_bin):
for x_n in range(num_bin):
for y_n in range(num_bin):
if ((M_0[x_n1, x_n, y_n] * M_3[x_n]) != 0) and (M_2[x_n, y_n] * M_1[x_n1, x_n] != 0):
#TE_Y2X += (M_0[x_n1, x_n, y_n] * np.log((M_0[x_n1, x_n, y_n] * M_3[x_n]) / (M_2[x_n, y_n] * M_1[x_n1, x_n])))
TE_Y2X += (M_0[x_n1, x_n, y_n] * math.log((M_0[x_n1, x_n, y_n] * M_3[x_n]) / (M_2[x_n, y_n] * M_1[x_n1, x_n]),num_bin)) #Using math.log(,num_bin)
return TE_Y2X
def cal_entropy(LR, num_bin):
Entropy_X = 0
M_3 = np.zeros(num_bin)
for t in range(len(LR)):
M_3[LR[t]] += 1
M_3 = M_3 / M_3.sum()
for x_n in range(num_bin):
if (M_3[x_n] != 0):
Entropy_X += (M_3[x_n] * math.log(1/ M_3[x_n], num_bin))
return Entropy_X
def cal_ETE_Y2X(TE_Y2X, RTE_Y2X):
return TE_Y2X- RTE_Y2X2.2 데이터 세팅 : Many to one
다음은 lstm 시계열 모델을 위해서 데이터를 세팅합니다. 시계열 모델의 input, output세팅은 크게 many to one, many to many이 가능합니다. many to one의 경우, 여러 time series의 값을 input으로 지정하고, output으로 단 하나의 값을 예측합니다. 예를 들어, 5일간의 값을 주고, 6일째의 값을 예측하는 것입니다. many to many의 경우, 여러 time series값을 주고, 여러 time series값을 output으로 도출합니다.
필자는 many to one setting을 사용하였습니다.
- num_lag : input의 기간(0~k);
- moving_window : transfer entropy 계산에 사용되는 기간; is_TE가 True일 시, input으로 추가
- pred_period : output의 target 날(k+p);
Model Input : num_lag동안의 log return bin값
Model Output : input의 마지막 log return bin k 대비 pred_period가 지난 날의 log return bin k+p가 증가했는지 여부 up(1)/down(0) 값

def create_dataset(company, market, moving_window, num_lag,num_bin, pred_period, prob,is_TE = True):
# //todo : in Paper, train 70% randomly sampled set in the training set
#sampled_company = company.sample(frac=0.7,random_state=200)
#sampled_market = market.sample(frac=0.7,random_state=200)
company_x, company_y = [],[]
print("** [Data]\n Total Len company : ",len(company),"\tLen market : ",len(market))
######################################################
if moving_window>num_lag:
for i in range(len(company)-(moving_window+pred_period)):
company_i = list(company.iloc[i+moving_window-num_lag:i+moving_window]['LR_bin'].values)
#market_i = list(market.iloc[i:i+num_lag]['LR_bin'].values)
company_mw = list(company.iloc[i:i+moving_window]['LR_bin'].values)
market_mw = list(market.iloc[i:i+moving_window]['LR_bin'].values)
if is_TE:
TE_inner = cal_TE_Y2X(company_mw, market_mw, num_bin = num_bin)
TE_outer = cal_TE_Y2X(market_mw, company_mw, num_bin = num_bin)
company_i.extend([TE_inner,TE_outer])
r_t_a = company.iloc[i+moving_window+pred_period-1]['LR_bin']
r_t_b = company.iloc[i+moving_window-1]['LR_bin']
r_t = company.iloc[i+moving_window+pred_period-1]['Log Return']
company_i_y = (r_t_a - r_t_b)>=0
#company_i_y = r_t>0
company_x.append(company_i)
company_y.append(company_i_y)
else:
for i in range(len(company)-(num_lag+pred_period)):
company_i = list(company.iloc[i:i+num_lag]['LR_bin'].values)
#market_i = list(market.iloc[i:i+num_lag]['LR_bin'].values)
company_mw = list(company.iloc[i+num_lag-moving_window:i+num_lag]['LR_bin'].values)
market_mw = list(market.iloc[i+num_lag-moving_window:i+num_lag]['LR_bin'].values)
if is_TE:
TE_inner = cal_TE_Y2X(company_mw, market_mw, num_bin = num_bin)
TE_outer = cal_TE_Y2X(market_mw, company_mw, num_bin = num_bin)
company_i.extend([TE_inner,TE_outer])
r_t_a = company.iloc[i+num_lag+pred_period-1]['LR_bin']
r_t_b = company.iloc[i+num_lag-1]['LR_bin']
r_t = company.iloc[i+num_lag+pred_period-1]['Log Return']
#company_i_y = (r_t_a-r_t_b)/r_t_b >0
company_i_y = (r_t_a - r_t_b)>=0
#company_i_y = r_t>0
company_x.append(company_i)
company_y.append(company_i_y)
######################################################
train_company_x, train_company_y,test_company_x, test_company_y = train_test_split(company_x, company_y,prob)
return train_company_x, train_company_y,test_company_x, test_company_y
def train_test_split(company_x, company_y, prob):
train_size = int(len(company_x)*prob)
train_company_x = torch.from_numpy(np.expand_dims(np.array(company_x[: train_size]), axis=-1)).type(torch.Tensor)
train_company_y = torch.from_numpy(np.array(company_y[: train_size])).type(torch.Tensor)
test_company_x = torch.from_numpy(np.expand_dims(np.array(company_x[train_size:]), axis=-1)).type(torch.Tensor)
test_company_y = torch.from_numpy(np.array(company_y[train_size:])).type(torch.Tensor)
print('train_company_x.size : ',train_company_x.size(),' | train_company_y.size : ',train_company_y.size())
print('test_company_x.size : ',test_company_x.size(),' | test_company_y.size : ',test_company_y.size())
return train_company_x, train_company_y,test_company_x,test_company_y3. LSTM
3.1 LSTM 모델
lstm 모델 구현
# Here we define our model as a class
class LSTM(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim,num_layers, drop_out,device):
super(LSTM, self).__init__()
# Hidden dimensions
self.hidden_dim = hidden_dim
# Number of hidden layers
self.num_layers = num_layers
self.device = device
# batch_first=True causes input/output tensors to be of shape
# (batch_dim, seq_dim, feature_dim)
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True,dropout = drop_out)
# Readout layer
self.fc1 = nn.Linear(hidden_dim, 16)
self.fc2 = nn.Linear(16, output_dim)
def forward(self, x):
# Initialize hidden state with zeros
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_().to(self.device)
# Initialize cell state
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_().to(self.device)
# We need to detach as we are doing truncated backpropagation through time (BPTT)
# If we don't, we'll backprop all the way to the start even after going through another batch
out, (hn, cn) = self.lstm(x, (h0.detach(), c0.detach()))
# Index hidden state of last time step
# out.size() --> #[1574,59,32]
# out[:, -1, :] --> #[1574,32] --> just want last time step hidden states!
#print('out size: ', out.size())
out = self.fc1(out[:, -1, :])
out = self.fc2(out)
out = torch.sigmoid(out)
return out3.2 Run LSTM
from torch.types import Device
def run(model_config,train_company_x, train_company_y,test_company_x, test_company_y, num_epochs, batch_size):
input_dim = model_config['input_dim']
hidden_dim = model_config['hidden_dim']
output_dim = model_config['output_dim']
num_layers = model_config['num_layers']
learning_rate = model_config['learning_rate']
drop_out = model_config['drop_out']
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = LSTM(input_dim=input_dim, hidden_dim=hidden_dim, output_dim=output_dim, num_layers=num_layers, drop_out = drop_out, device = device).to(device)
#loss_fn = torch.nn.MSELoss()
loss_fn = torch.nn.BCELoss() #Binary
#loss_fn = torch.nn.CrossEntropyLoss() #Multi
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
print('** [Model Description]\n',model)
#Dataset
train_dataset = TensorDataset(train_company_x, train_company_y)
#Dataloader
train_loader = DataLoader(dataset = train_dataset, batch_size = batch_size, shuffle= True)
total_loss = []
for epoch in range(num_epochs):
running_loss = 0.0
running_acc = 0.0
# Forward pass
for i, (batch_x, batch_y) in enumerate(train_loader):
batch_pred_y = model(batch_x.to(device))
loss = loss_fn(batch_pred_y, batch_y.unsqueeze(dim = -1).to(device))
optimizer.zero_grad()
loss.backward()
#torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
running_loss+=loss.item()
batch_pred_tag = torch.round(batch_pred_y)
running_acc += np.sum(np.equal(batch_pred_tag.detach().cpu().numpy().squeeze(), np.array(batch_y)))
if epoch % 100 == 0 and epoch !=0:
print("Epoch : ", epoch, "Running loss: ", running_loss, 'Acc: ', running_acc/len(train_company_x))
total_loss.append(running_loss)
#Plot training loss
plot_train_loss(total_loss)
#Evaluation
test_pred_y = model(test_company_x.to(device))
test_acc = eval_acc(test_pred_y, test_company_y.to(device))
return test_pred_y, test_acc
def plot_train_loss(total_loss):
plt.plot(total_loss, label="Training loss")
plt.legend()
plt.show()
def eval_acc(test_pred_y, test_company_y):
with torch.no_grad():
#Var1. Binary
test_pred_tag = torch.round(test_pred_y)
test_acc = np.sum(np.equal(test_pred_tag.detach().cpu().numpy().squeeze(),test_company_y.detach().cpu().numpy()))/ len(test_company_y.detach().cpu().numpy())
print("** [Eval Result]\n Check ")
print("pred: ",test_pred_tag.detach().cpu().numpy().squeeze()[:30])
print("y: ",test_company_y[:30])
#Var2. Multi
#outputs = torch.nn.Softmax(dim=1)(test_pred_y)
#test_acc = (outputs.argmax(1) == test_company_y).sum().item() /len(test_company_y)
print('Test Score: %.5f' % (test_acc))
return test_acc
full 코드는 여기서 확인하실 수 있습니다 :)
ㅇㅇ
'기타' 카테고리의 다른 글
| Torch 기본 (0) | 2022.12.02 |
|---|---|
| 논문 리뷰 파이프라인 (2) | 2022.05.03 |
| [Review] Matchmaking in Lyft Line (0) | 2022.01.14 |
| Docker Swarm 분산 서버 관리 (0) | 2021.04.19 |