Tensor
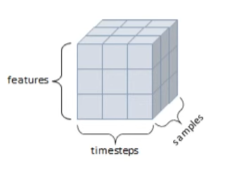
- 3D Tensor :
t3.ndim = 3
시계열 데이터 (feature / timestep/ sample)
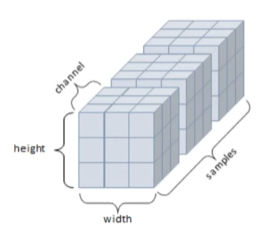
- 4D Tensor :
t4.ndim = 4
컬러 이미지 (height, width, channel, sample)
Tensor 연산
torch.abs(a)
torch.ceil(a)
torch.floor(a)
torch.clamp(a, -0.5,0.5)
torch.std(a)
torch.prod(a)
torch.unique(a)
a.max(dim = 0) #dim 지정시, argmax 와 같이 작동
a.min(dim = 1) # dim 지정시, argmin처럼 index함께 반환
in-place방식 : 텐서의 값을 변경하는 연산 뒤에 underbar '_' 붙음
y.add_(x) #y +=x
x.sub(y)
x.mul(y)
x.div(y)
torch.matmul(x,y) = torch.mm(x,y) #dot product
Tensor 조작
- view: 텐서의 크기(size)와 모양(shape) 변경
x = torch.randn(4,5)
y = x.view(20)
z = x.view(5,-1) #(5,4)
x.item() # scalar값에만 item()적용 가능
- squeeze : 차원을 축소(제거)
x = torch.rand(1,3,3)
x.shape #[1,3,3]
x.squueze #[3,3]
- unsqueeze : 차원을 증가(생성)
x = torch.rand(3,3)
x.unsqueeze(dim = 0) #[1,3,3]
x.unsqueeze(dim = 2) #[3,3,1]
- stack : 텐서간 결합
torch.stack([x,y,x])
- cat : 텐서 결합하는 메소드 / 원하는 결합 기준 dim 명시해야함
a = torch.rand(1,3,3)
b = torch.rand(1,3,3)
c = torch.cat((a,b), dim = 0)
c.shape #[2,3,3] c.size()와 같음
d = torch.cat((a,b), dim = 1)
d.shape # [1,6,3]
- chunk : 텐서를 여러개로 나눌 때 사용 # 몇개로 나눌 지 지정
t = torch.rand(3,6)
t1, t2, t3 = torch.chunk(t, 3, dim = 1)
t1.shape #t2.shape #t3.shape : 모두 [3,2]
- split : chunk와 동일 기능이지만 조금 다름 # 텐서의 크기를 지정
t = torch.rand(3,6)
t1, t2 = torch.split(tensor, 3, dim = 1)
t1.shape # [3,3]
torch & numpy
tensor가 cpu상에 있다면, numpy 배열은 메모리 공간을 공유하므로 하나가 변하면, 다른 하나도 변함
a = torch.ones(2)
b = a.numpy()
a.add_(1)
a #[2., 2.,]
b #[2 2] b도 변함!
a= np.ones(2)
b = torch.from_numpy(a)
np.add(a,1,out = a)
a #[2,2]
b #[2,2] b 도 변함
Autograd(자동미분)
requires_grad = True설정시 해당 텐서에서 이루어지는 모든 연산들을 추적하기 시작
기록 추적을 중단하려면, .detach()를 호출하여 연산기록으로부터 분리!
grad_fn : 미분값을 계산한 함수에 대한 정보 저장 / 어떤 함수에 대해서 backprop했는지
a.requires_grad_(True)
b = (a*a).sum()
print(b)
print(b.grad_fn) # SumBackward0
Gradient 기울기
y = x+5
y #grad_fn = AddBackward
z = y*y
z #grad_fn = MulBackward
out = z.mean()
out #grad_fn = MeanBackward
계산이 완료된 후, .backward()를 호출하면 자동으로 역전파 계산이 가능하고, .grad속성에 누적됨
grad: data가 거쳐온 layer에 대한 미분값 저장
out.backward() #grad_fn = MenaBackward
with torch.no_grad() : 기록 추적 방지
기울기의 업데이트를 하지 않아서(requires_grad = False로 변경) 모델을 평가할 때 유용
detach() : 내용물은 같지만, require_grad가 다른 새로운 Tensor를 가져올 때
x.requires_grad #True
y = x.detach()
print(y.requires_grad) #False
print(x.eq(y).all()) #True
자동 미분 흐름 예제
연산 흐름 a-->b-->c-->out
backward()를 통해 a<--b<-- c<-- out 을 계산하면 \partial(out) / \partial(a)값이 a.grad에 채워짐
a = torch.ones(2,2, requires_grad= True)
b = a+2 #grad_fn = AddBackward
c = b**2 #grad_fn = PowBackward
out = c.sum() #out = SumBackward
out.backward()
a.grad
a.grad_fn #None : 직접적으로 계산한 부분이 없기 떄문에
b.grad #None
데이터 준비
torch.utils.data.Dataset & torch.utils.data.DataLoader 사용가능 : batch_size, train여부, transfrom등을 인자로 넣어 데이터를 어떻게 load할 것인지 지정
torchvision :파이토치에서 제공하는 데이터셋들이 모여있는 패키지 / torchvision이 PIL image형태로만 입력을 받기 때문에 ToTensor()필요
mnist_transfom = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean = (0.5.), std = (1.0.))])
DataLoader는 데이터 전체를 보관했다가 실제 모델 학습시에 batch_size만큼 데이터를 가져옴
dataiter = iter(train_loader)
images, labels = dataiter.next()
신경망 구성 import torch.nn as n
layer : 텐서를 입력받아 텐서 출력
module : 1개 이상의 layer 모여서 구성
model : 1개 이상의 module로 구성
- nn.Linear(in-feature, out-feature)
grad_fn = AddmmBackward
- nn.Conv2d(in_channels = 16,out_channels = 33, kernel_size = (3,5) ,stride = (2,1)).to(device)
import torch.nn.functional as F
pool = F.max_pool2d(output, 2,2)
선형 layer
flatten = input_image.view(1, 28*28)
lin = nn.Linear(784,10)(flatten)
lin.shape #[1,10]
비션형활성화 non-linear activation
with torch.no_grad():
flatten = input_image.view(1, 28*28)
lin = nn.Linear(784,10)(flatten)
softmax = F.softmax(lin, dim = 1)
nn.Module을 상속받는 클래스 정의
__init__() :모델에서 사용될 모듈과 활성화 함수 정의
forward() : 모델에서 실행되어야 하는 연산 정의
list(model.modules())
nn.Sequential 객체로 그 안에 각 모둘을 순차적으로 실행
self.layer1 = nn.Sequential(
nn.Conv2d(3, 64, 5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
)
x = self.layer1(x)
모델 파라미터
- 손실함수 Loss function
예측값과 실제 값 사이의 오차 측정 / 최소화하고자 함/ 미분가능한 함수 사용
torch.nn.BCELoss : 이진분류
torch.nn.CrossEntropyLoss :다중분류
torch.nn.MSELoss :회귀 모델에서 사용
- 옵티마이저 Optimizer
손실함수 기반으로 모델이 어떻게 업데이트 되어야하는지 결정
Learning rate scheduler : 학습시 특정조건에 따라 학습률을 조정하여 최적화 진행
optim.Adam / optim.SGD
- 지표 Metrics
!pip install torchmetrics
import torchmetrics
acc = torchmetrics.functional.accuracy(preds, target)
모델 저장
PATH = './fashion.pth'
torch.save(net.state_dict(),PATH)
net = NeuralNet()
net.load_state_dict(torch.load(PATH))
'기타' 카테고리의 다른 글
| LSTM으로 주식 가격 예측하기 (0) | 2022.12.05 |
|---|---|
| 논문 리뷰 파이프라인 (2) | 2022.05.03 |
| [Review] Matchmaking in Lyft Line (0) | 2022.01.14 |
| Docker Swarm 분산 서버 관리 (0) | 2021.04.19 |