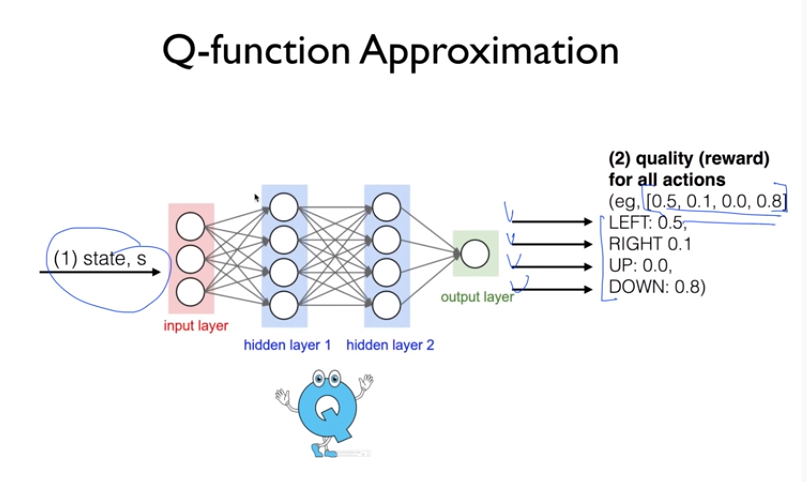
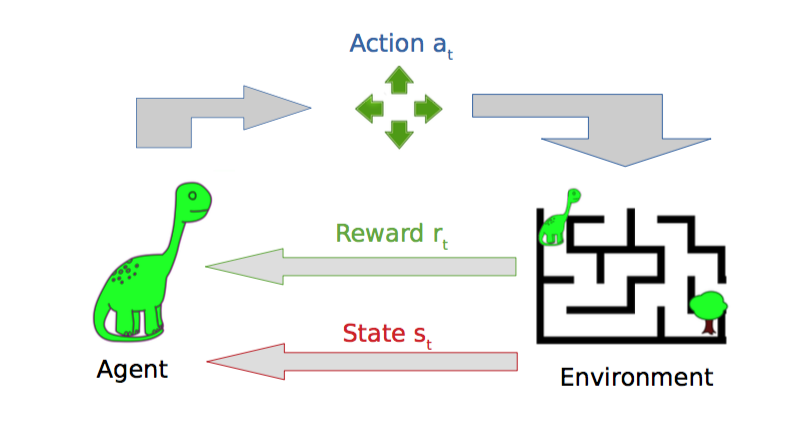
다음 강의와 '파이썬과 케라스로 배우는 강화학습' 도서를 보고 정리한 내용입니다 : ) www.youtube.com/watch?v=gINks-YCTBs 'RLCode와 A3C 쉽고 깊게 이해하기' Asynchronous Advantage Actor-Critic, A3C가 강화학습의 새로운 베이스라인으로 자리잡았다. DQN의 장단점 + 게임 화면 이미지 자체를 input으로 받아 CNN을 통해 학습 + 샘플 간 높은 상관관계의 문제를 '리플레이 메모리'를 통해 해결 - 많은 메모리 사용 - 느린 학습속도 - 가치함수에 대한 Greedy Policy로 학습이 다소 불안정 A3C + 샘플 간 높은 상관관계의 문제를 '비동기 업데이트'로 해결 -> 리플레이 메모리 더이상 사용 X + Policy gradient..