다음 강의와 '파이썬과 케라스로 배우는 강화학습' 도서를 보고 정리한 내용입니다 : )
www.youtube.com/watch?v=gINks-YCTBs
Asynchronous Advantage Actor-Critic, A3C가 강화학습의 새로운 베이스라인으로 자리잡았다.
DQN의 장단점
+ 게임 화면 이미지 자체를 input으로 받아 CNN을 통해 학습
+ 샘플 간 높은 상관관계의 문제를 '리플레이 메모리'를 통해 해결
- 많은 메모리 사용
- 느린 학습속도
- 가치함수에 대한 Greedy Policy로 학습이 다소 불안정
A3C
+ 샘플 간 높은 상관관계의 문제를 '비동기 업데이트'로 해결 -> 리플레이 메모리 더이상 사용 X
+ Policy gradient 알고리즘 사용가능 --> Actor Critic
+ 여러 에이전트가 환경과 상호작용하므로써 상대적으로 빠른 학습속도
강화학습의 크로스 엔트로피
입력 -> 인공신경망('정책'을 근사) -> 출력(각 행동을 할 확률 ex.상하좌우) = 예측 P / 실제 에이전트가 한 행동= 정답 Y
이때, 실제 에이전트가 한 행동을 정답으로 두는 것은 아무 의미가 없으므로 업데이트의 방향성이 필요하다 --> Q 함수
크로스엔트로피에 Q값(크리틱)을 곱하고 이를 통해 Gradient descent를 계산한다.

A3C
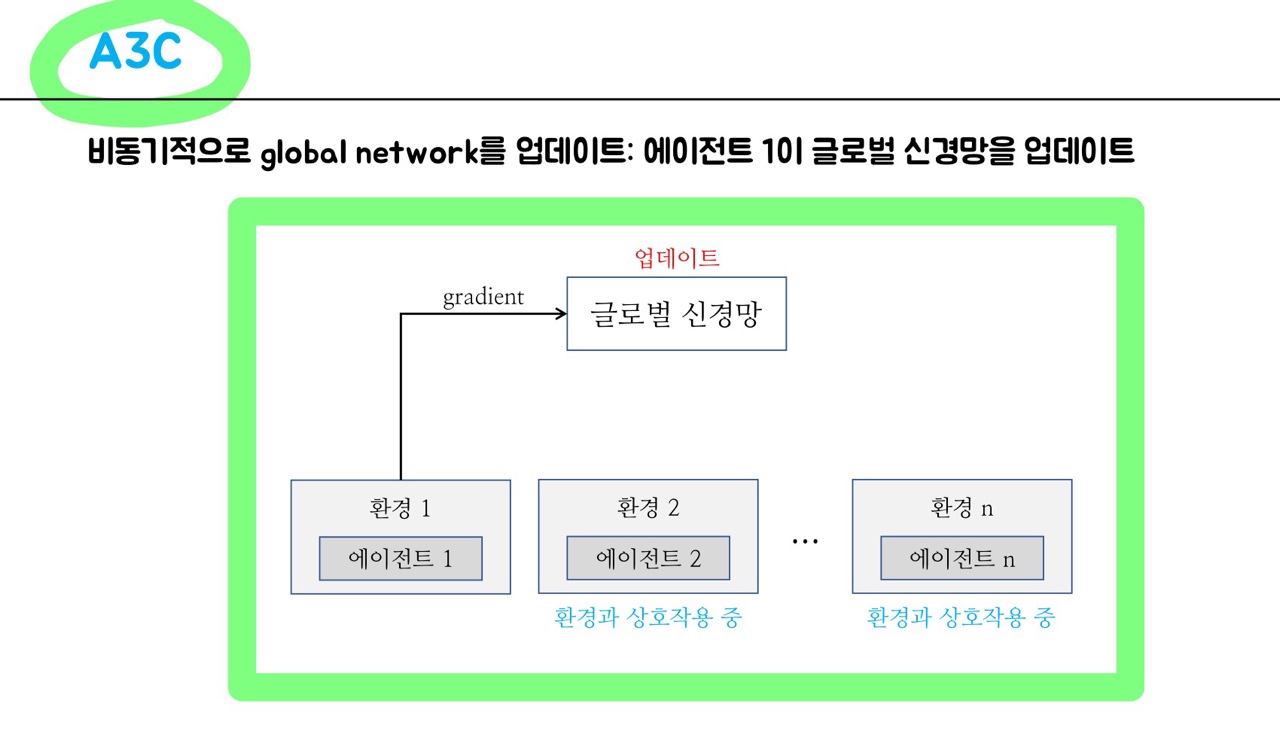
다수의 에이전트들이 환경과 상호작용하면서 하나의 글로벌 신경망을 업데이트함.
'에이전트1이 글로벌 신경망을 업데이트 & 업데이트 된 글로벌 신경망으로 에이전트1을 역으로 업데이트'하는 동안에 나머지 에이전트들은 각자의 환경과 상호작용하면서 샘플을 모으고 있음.
A3C를 이해하기 위해서 필요한 이해 과정
1) Policy Gradient -> 2) Reinforece알고리즘 -> 3) Actor-Critic -> 4) A3C
Policy Gradient를 몬테카를로 방식으로 사용한 Reinforce알고리즘
Reinforce알고리즘을 On-line실시간으로 사용하게 된 Actor-Critic
다수 에이전트가 비동기식 업데이트하는 A3C
1) Policy Gradient
현재 정책을 환경으로 부터 받은 보상에 근거한 기준으로 업데이트 해야함.
어떤 기준 이 필요하고 그 기준대로 어떻게 업데이트할지에 대한 방법 이 필요!
= 목표함수 = Gradient ascent
이때, 스케일이 커지면 모든 state에 대한 개별 정책(행동)을 설정하기 힘들기에 정책을 함수화 시키는 과정이 필요한데, 이를 '정책의 근사화'라고 함. 특정 입력을 '정책이라는 함수'에 넣어 출력값(행동)을 얻음.
- 목표함수 J(θ)
정책 기반 강화학습에 쓰이는 기준으로, 정책을 업데이트할 떄 어떤 방향으로 업데이트 할 지에 대한 기준.
J(θ) =경로 동안 받을 것이라고 기대되는 보상의 합
경로 Τ = 에이전트와 환경이 상호작용한 흔적(s, a, r, ... )
- Gradient Ascent
보통의 loss function은 최소화시켜야 하기에 gradient descent 를 하였지만,
목표함수J(θ)는 최대화 시켜야하는 긍정적인 값 :)
따라서 J(θ)의 경사를 따라서 올라가는 gradient ascent 방법으로 업데이트를 진행함.

2) REINFORCE 알고리즘
REINFORCE알고리즘의 핵심은 아래식을 유도하여 하나의 에피소드마다 목표함수를 업데이트를 진행해나가는 것
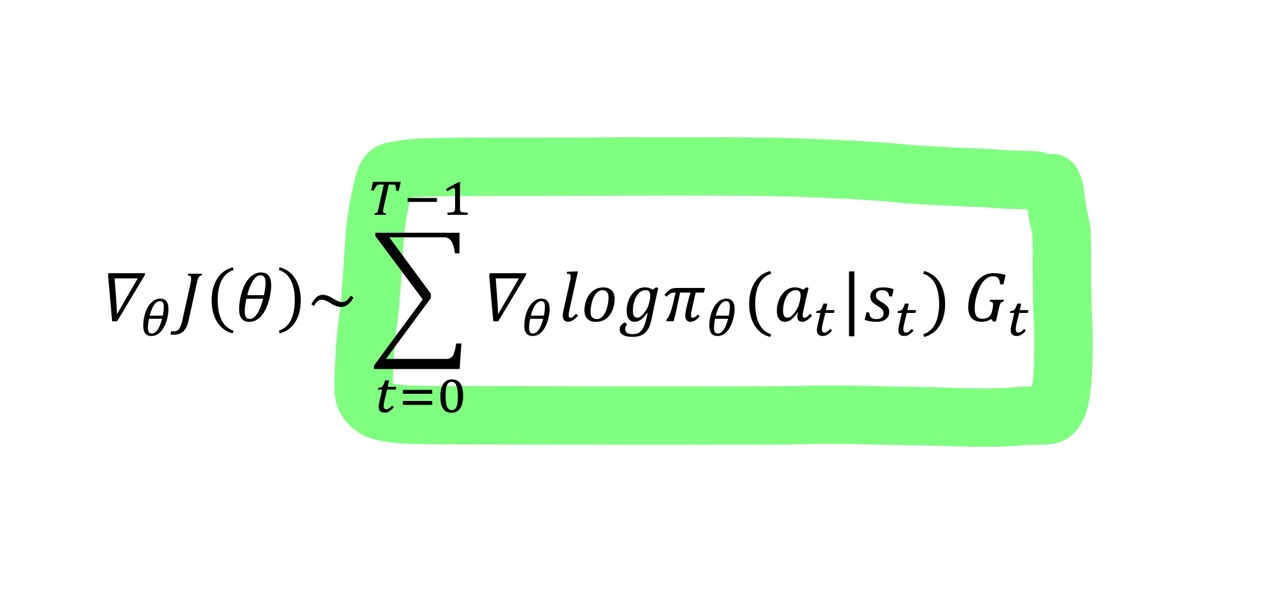
- Reinforce 알고리즘 단계
(1) 한 에피소드를 현 정책에 따라 실행
(2) Trajectory경로를 기록
(3) 에피소드가 끝난 뒤 각 스텝별 모든 Gt 값을 계산
(4) Policy gradient를 계산하여 정책을 업데이트 --> '몬테카를로' 방법(하나의 에피소드가 끝난 후에 업데이트 가능)
(5) 위 1~4 스텝을 반복
- Reinforce 알고리즘 문제
에피소드가 길어질수록 Variance가 높아짐.
on-line이 아니라 하나의 에피소드가 끝나야 업데이트 가능함.
- 수식 유도 과정
(자료 참고)
3) Actor Critic
Reinforce알고리즘에서 유도한 미분값을 쪼개보았을 때, Q함수를 발견가능.
따라서, Q함수의 값을 알고만 있다면 매 time-step별로 업데이트가 가능! --> Q함수를 뉴럴넷으로 근사하자~!

이때, Variance를 낮추기 위해 Advantage함수 사용! 정규화와 비슷한 개념!
Advantage 함수 = Q함수 - 베이스라인(전반적인 행동값,평균) // TimeDifference(TD)라고도함.
베이스라인으로 가치함수(특정상태에서 앞으로 받을 보상에 대한 전반적인 값)을 사용할 수 있고,
Q함수도 가치함수를 통해 표현이 가능하기 때문에
최종적으로 Advantage함수를 가치함수로 표현하고 가치함수만 뉴럴넷을 사용하여 근사함.

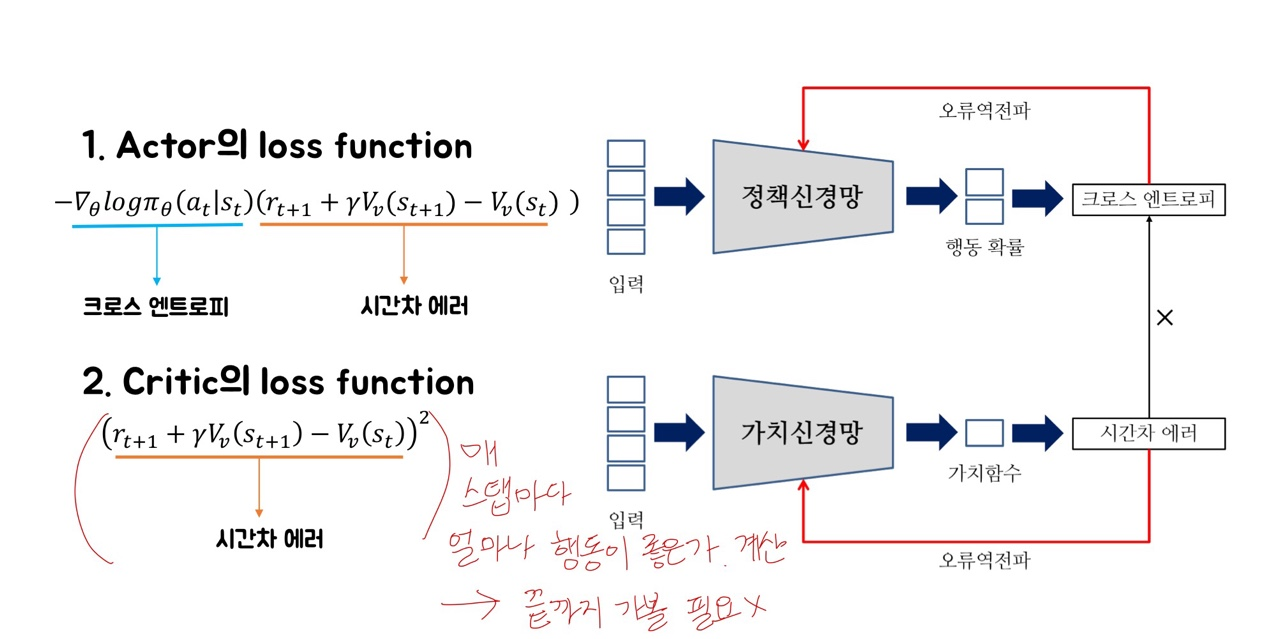
결론적으로, Actor-Critic은 'Actor = 정책을 근사' + 'Critic = 가치함수를 근사'
햔제 state가 input으로 들어오면 정책신경망의 정책을 통해서 다음 action을 결정.
그 뒤 환경env으로 부터 다음state'와 보상reward을 받음.
이 값으로 Critic '가치신경망' 통해 시간차에러를 구함. 이 시간차 에러는 가치신경망을 업데이트하는 데 사용되며,
동시에, 크로스 엔트로피와 곱해져서 Actor '정책신경망'을 업데이트하는 loss function을 구하는데 사용됨.
새롭게 계산한 Actor의 loss function으로 정책신경망을 업데이트함.

4) A3C
- A3C가 Actor-Critic과 다른점
(1) multi-step loss funciton
--> multi-agent가 하나의 global network를 업데이트하기에, 하나의 에이전트가 global network 업데이트 할 동안 나머지 agent는 여러 스텝을 진행하면서 업데이트 할 타이밍을 기다림. 이때, 모든 step마다 loss function을 구해서 더한 것으로 업데이트함. (ex. 20step -> 20개의 loss function을 더한것으로 업데이트)
(2) Entropy loss function을 더함 --> 끊임없는 Exploration을 통해서 더 나은 경로를 찾아갈 수 있도록.

결론적으로, 각각 자신의 환경을 가진 여러개의 에이전트과 하나의 global network간의 상호작용으로 업데이트가 진행.


Reference:
[1]: www.youtube.com/watch?v=gINks-YCTBs
[2]: www.slideshare.net/WoongwonLee/rlcode-a3c
'ML&DL > Reinforcement Learning' 카테고리의 다른 글
| Basic RL (0) | 2023.02.23 |
|---|