목차
강화학습의 적용분야는 상당히 넓다. Optimal decision making하는 분야라면 다 적용가능하다!
RL과 다른 머신러닝의 차이점은 agent가 action(환경과의 상호작용)을 통해 얻는 reward signal(delay 될 수 있음)이다.


Reward
agent 가 받는 피드백으로, 현재 timestep t에서 얼마나 잘했는가를 알 수 있다.
agent는 cumulative reward를 최대화해야한다.
RL reward hypothesis : 모든 goal은 expected cumulative reward의 최대화로 표현 가능하다. (동의하는가?!)
History
현재 timestep t까지의 일련의 observation, action, reward를 의미한다.
H_t = O_1, R_1, A_1, ..., O_t, R_t
State
다음 timestep에 무엇을 할 지 결정하기 위해 사용하는 정보로, funtion of the history이다. S_t = f(H_t)
이때 funtion은 정의하기 나름! eg. f(H_t) = last observation (O_t)
state는 environment state, agent state, information state(Markov state)가 존재한다.
environment state는 주로 agent가 알지 못한다. agent state는 agent가 다음 action을 선택할 때 사용하는 정보이다.
information state란, history에서 모든 유용한 정보를 포함하고 있다. 중요한 개념이니, 아래에 따로 설명!
Markov
"The future is independent of the past given the present"
Markov의 정의는 특정 state가 과거의 history 정보를 다 아우를 수 있을 때를 말한다.
따라서 environment state는 Markov이다. environment 입장에서는 과거가 현재 무엇을 할 지 영향을 미치지 않기 때문이다. 현재만 중요!
그리고 당연히, history H_t 는 그 자체로 Markov이다.

MDP / POMDP
MDP는 Markov decision process로 agent가 environment state를 직접적으로 관찰할 수 있을 때를 말한다.
agent state = environemtn state = information state
POMDP는 Partially observalble Markov decision process로 agent가 environment 일부 관찰 가능하다.
그래서 agent가 state를 어떻게 표현할 건지 정의가 필요하다.
option으로는, complete history / beliefs of environment state(probability distribution으로 이럴거야.. ) / RNN(과거 stare와 현재 observation 합치기) 가 있다.
Policy
agent의 행동 정책을 의미한다. map state to action
deterministic policy(하나의 state에는 단 하나의 action), stochastic policy(여러 action에 대한 probabiltiy)가 존재한다.
Value Funciton
Prediction of future reward로 특정 state가 얼마나 좋은지 평가하는데 사용한다.
이 값은 policy에 따라 다르다. 현재 policy에서 해당 state의 가치!
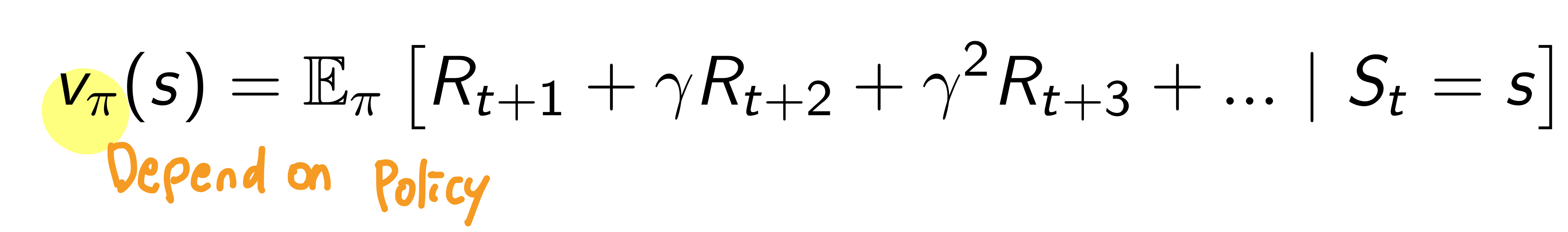
Model
Predict what the environment will do next!! 어떤 state? reward는 몇??
Transition model은 다음 state가 무엇일지 예측한다.
Reward는 모델은 (state,action)에 따라 reward를 얼마나 부여할 지 예측한다.
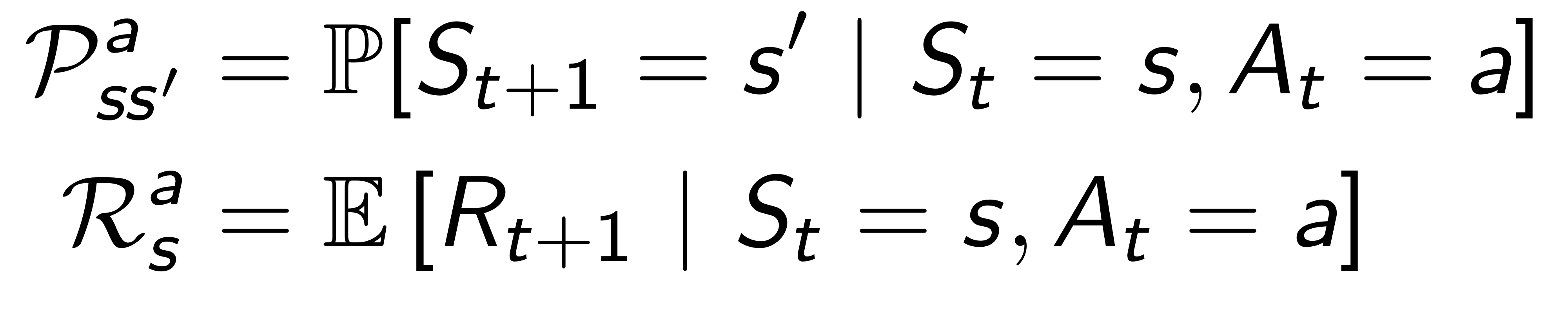
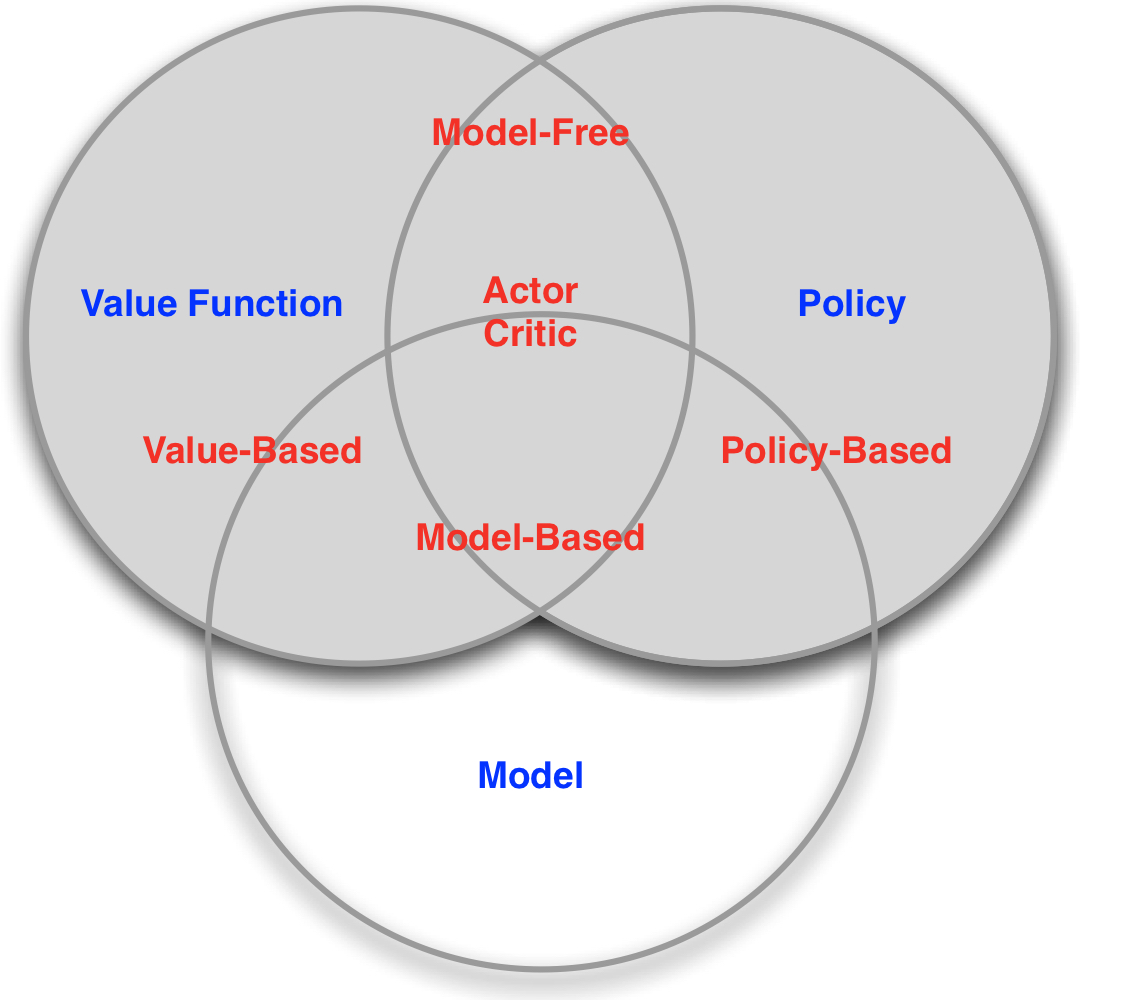
Value Based / Policy Based / Actor Critic
Value based는 value function을 구성하고 이에 따라 action을 고른다. 따라서 policy가 필요없음!(value funciton에 따라 높은 값을 고르면 되므로)
Policy based는 반대로 value function 대신, policy를 직접적으로 구성하는 방법이다.
Actor critic은 value funciton과 policy 둘다 가진다.
Model Free / Model Based
Model Free는 Model(transition, reward)를 알려고 하지 않고 policy 또는 value funciton을 사용한다.
Model based는 model에 대한 정보가 (환경을 알고) 있는 경우이다.
RL vs Planning
RL : 환경 모름/ 환경과 상호 작용 / plicy를 개선함
planning : 환경 앎(게임 룰을 사전에 알고있음)/ 상호 작용 없음 / policy를 개선함
Exploration & Exploitation
Exploration : 환경에서 더 많은 정보를 찾으려고 시도 eg. 새로운 음식점 탐색
Exploitation : reward를 최대화하기 위한 기존 알고있는 정보 활용 eg. 이미 알고있는 맛집 방문
Prediction and Control
RL은 Control problem을 풀기 위해 prediction problem을 해결한다.
Prediction이란 주어진 policy에서 미래를 평가하는 것. 얼만큼 reward를 얻을까? eg. value function은 무엇이지?
Control은 미래를 optimize하는 것. 최고의 정책을 찾자!!
'ML&DL > Reinforcement Learning' 카테고리의 다른 글
| PolicyGradient + REINFORCE + ActorCritic +A3C (0) | 2021.02.25 |
|---|