LEC 07
앞선 강의에서 Qnetwork 방법만으로는 Cart Pole 문제가 잘 풀리지 않았다.

두가지 문제점이 있는데,
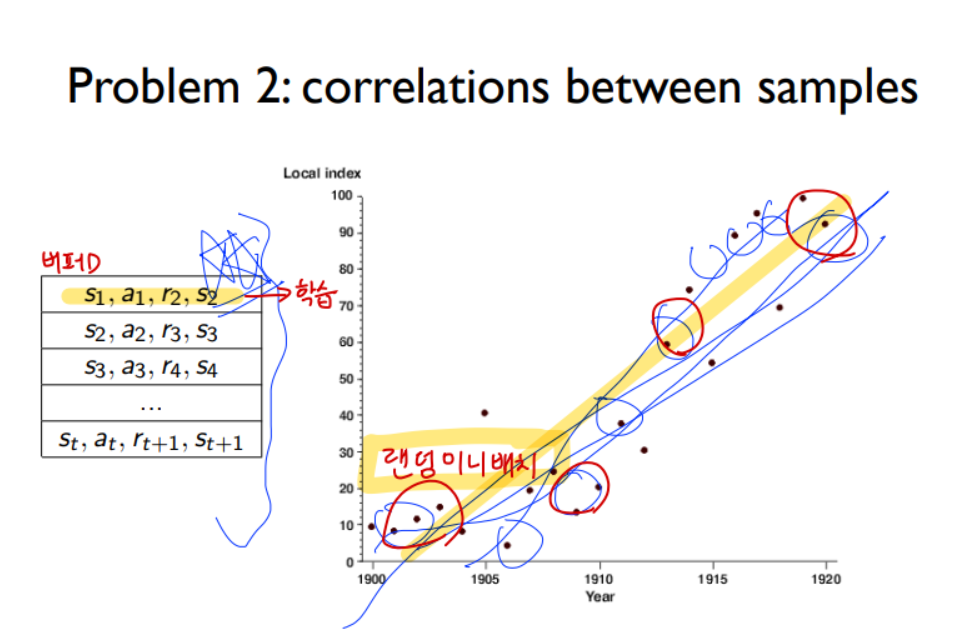
1) 샘플 간의 상관관계와 2)타겟값이 고정이 안된다는 것이다.

(1) 다음과 같이 상관관계가 높은 샘플만으로 학습을 시키면 목표하는 값과 상당히 다른 결과를 가진다.

(2) Yhat 이 Y 가 될 수 있도록 θ를 업데이트 한다. 하지만, 예측과 target 이 모두 같은 네트워크를 사용하기 때문에, 학습과정에서 씨타를 업데이트 하는 순간, 동시에 target Y도 영향을 받아 움직이게 된다. 강의에서는 과녁을 보고 화살을 쏜 순간, 과녁이 움직여버린다고 하였다. 이런 이유 떄문에 학습이 어렵다.

Google Deep Mind팀은 다음 3가지 방법으로 문제를 해결하였다.
1) Go deep 네트워크 layer 층 깊게,
2) Capture and replay 버퍼저장 후 random.sample 미니배치로 학습 --> 상관관계 문제 해결
3) Seperate networks 예측과 target 네트워크 분리하기 --> target값 고정 안되는 문제 해결

(1) 네트워크의 층을 늘린다.
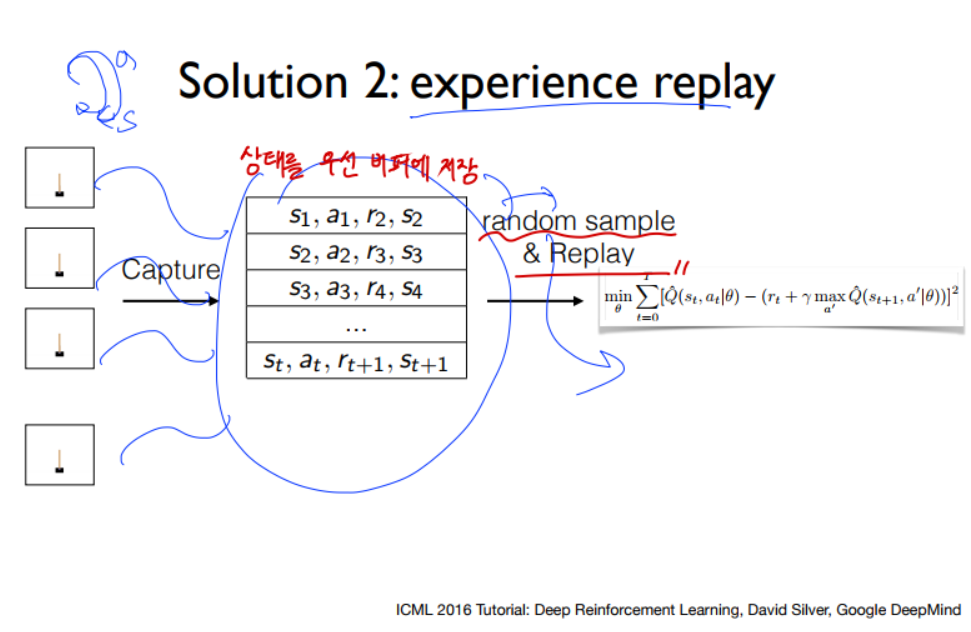
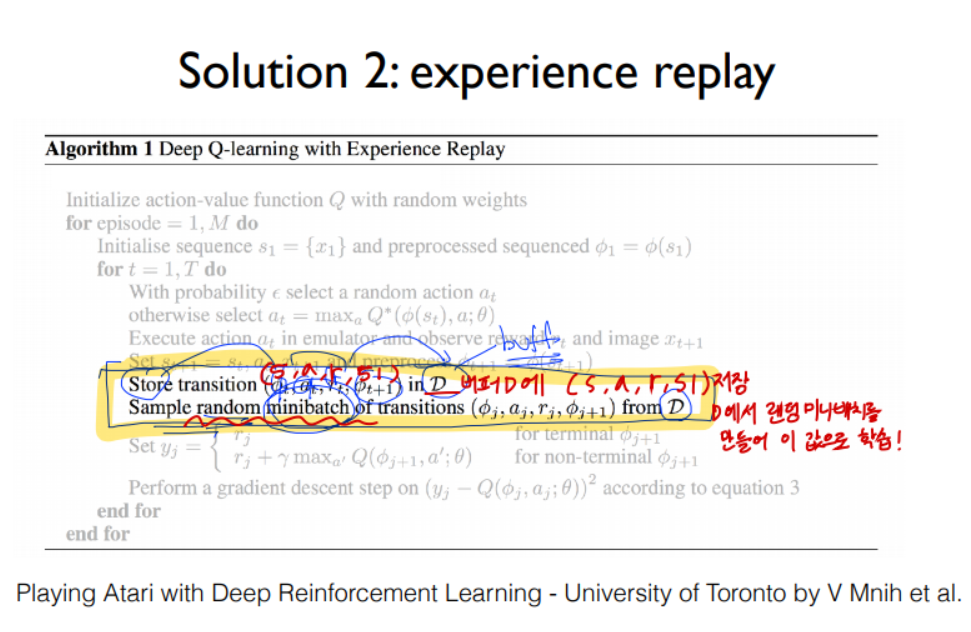
(2) env.step(action)에 대한 return값을 바로 학습에 사용하지 않고, 버퍼에 저장해둔다.
그 다음, random.sample 로 미니배치를 구해 한번에 학습시킨다.
random.sample 이 참 중요한 부분인데, 이를 통해 상관관계가 높은, 지역적인 값으로 학습되는 문제를 방지할 수 있다.
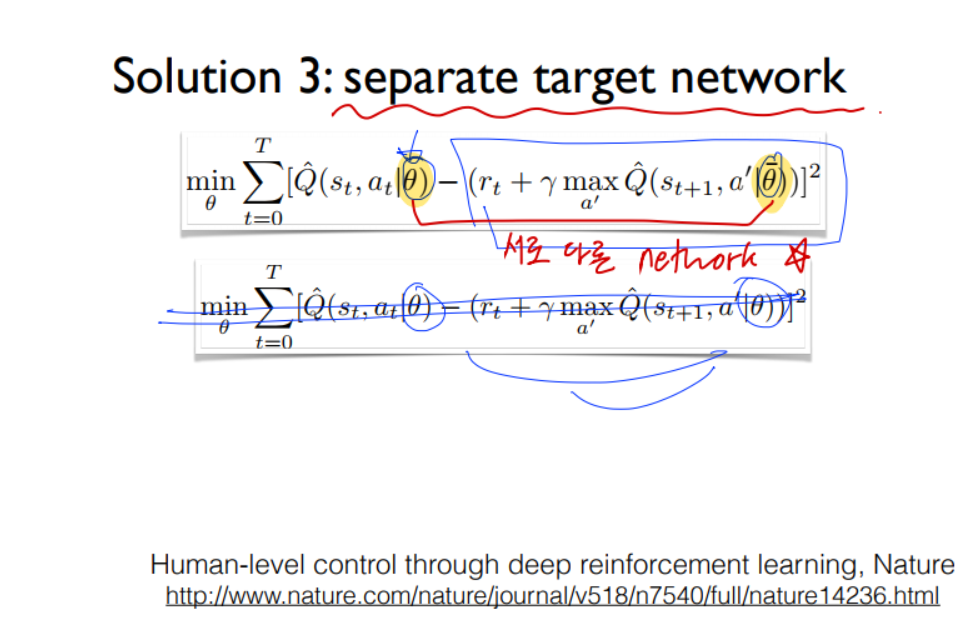
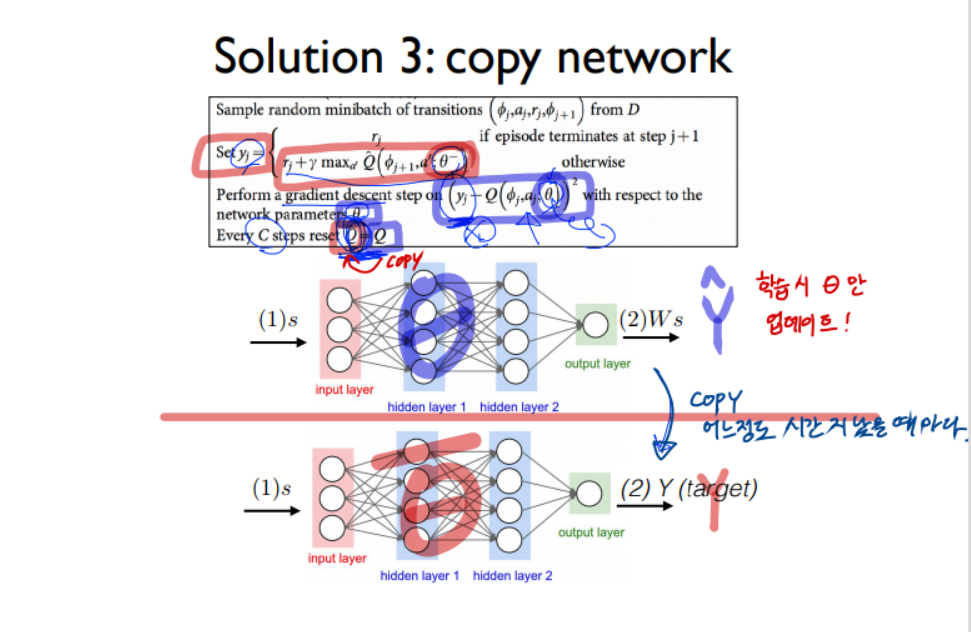
(3) 예측(파랑)과 target(빨강)에 사용하는 네트워크를 분리한다.
학습시에는 예측 네트워크만 업데이트하다가, 어느정도 시간이 지나면(C steps)
예측 네트워크를 target 네트워크에 복사한다.

LAB 07
CartPole DQN
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
|
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import random
from collections import deque
import gym
env = gym.make('CartPole-v0')
env._max_episode_steps = 10001 #최대 스텝을 10001로 늘려줌(기본 200으로 제한)
input_size = env.observation_space.shape[0]
output_size = env.action_space.n
dis = .9
REPLAY_MEMORY = 50000
class DQN:
def __init__(self, input_size, output_size, name='main'):
self.input_size = input_size
self.output_size = output_size
self.net_name = name
self._build_network()
def _build_network(self, h_size=10, l_rate=1e-1):
self._model = tf.keras.Sequential([
tf.keras.layers.Dense(10, input_shape=[self.input_size], activation = tf.nn.tanh ),
tf.keras.layers.Dense(output_size)
])
self._model.compile(optimizer = tf.keras.optimizers.Adam(learning_rate = l_rate), loss = 'mse')
self._model.summary()
def predict(self, state):
x = np.reshape(state, [1,self.input_size])
return self._model.predict(x)
def update(self, x_stack, y_stack):
hist = self._model.fit(x_stack, y_stack, verbose=0)
return hist
def get_weights(self):
return self._model.get_weights()
def set_weights(self, src_model):
return self._model.set_weights(src_model.get_weights())
def get_copy_var_ops(dest_model, src_model): # 타켓모델로 복사
dest_model.set_weights(src_model)
def replay_train(mainDQN, targetDQN, train_batch): # mainDQN 학습시키기
x_stack = np.empty(0).reshape(0, mainDQN.input_size)
y_stack = np.empty(0).reshape(0, mainDQN.output_size)
for state, action, reward, next_state, done in train_batch:
Q = mainDQN.predict(state)
if done:
Q[0, action] = reward
else:
Q[0, action] = reward + dis*np.max(targetDQN.predict(next_state))
y_stack = np.vstack([y_stack, Q])
x_stack = np.vstack([x_stack, state])
return mainDQN.update(x_stack, y_stack)
def bot_play(mainDQN): # 게임 플레이 보여주기
s = env.reset()
reward_sum = 0
while True:
env.render()
a = np.argmax(mainDQN.predict(s))
s, reward, done, _ = env.step(a)
reward_sum += reward
if done:
print("Total Score:{}".format(reward_sum))
break
env.close()
def main():
max_episodes = 5000
replay_buffer = deque()
mainDQN = DQN(input_size, output_size, name = 'main')
targetDQN = DQN(input_size, output_size, name = 'target')
get_copy_var_ops(dest_model = targetDQN, src_model = mainDQN) #시작 2개 네트워크 동일하게 하기
for episode in range(max_episodes):
e = 1./((episode/10)+1)
done = False
step_count = 0
state = env.reset()
while not done:
if np.random.rand(1)<e:
action = env.action_space.sample()
else:
action = np.argmax(mainDQN.predict(state))
next_state, reward, done, _ = env.step(action)
if done:
reward = -100
replay_buffer.append((state, action, reward, next_state, done))
if len(replay_buffer) > REPLAY_MEMORY:
replay_buffer.popleft()
state = next_state
step_count+=1
if step_count > 10000: #10000번 넘어가면 너무 잘하니 그만~
break
print("Episode: {} steps: {}".format(episode, step_count))
if step_count>10000:
pass
if episode % 10 ==1: # 10번마다 학습진행
for _ in range(50): # 총 50번*10개 sample로 학습
minibatch = random.sample(replay_buffer, 10)
hist = replay_train(mainDQN, targetDQN, minibatch)
print("Loss: ", hist.history['loss'])
get_copy_var_ops(targetDQN, mainDQN) # targetDQN으로 복사
if __name__ == '__main__':
main()
|
cs |
Reference:
[1]: hunkim.github.io/ml/
[2]: youtu.be/S1Y9eys2bdg
[3]: youtu.be/Fbf9YUyDFww
[4]: youtu.be/ByB49iDMiZE
'ML&DL > Sung Kim's RL Lecture' 카테고리의 다른 글
| LEC 06. Q-Network (0) | 2021.01.08 |
|---|---|
| LEC 05. Q-learning on Nondeterministic Worlds! (0) | 2021.01.08 |
| LEC 04. Q-learning (table) (0) | 2021.01.07 |
| LEC 03. Dummy Q-learning (table) (0) | 2021.01.07 |
| LEC 02. Playing OpenAI GYM Games (0) | 2021.01.06 |